



How economics can address the mounting problem of data waste
The problem
Every day the world’s use of digital data consumes vast amounts of energy, from data stored and processed on cloud servers and on-premise data centers, to data used on industrial and consumer devices and machines. Moving data, processing, copying and storing it, all requires copious amounts of energy, as well as other natural resources such as water, minerals and land. It is not just our personal or professional use of data that matters - it is more to do with the system-wide ripples that are generated when we do things like ping a photo to friends or implement training machine learning (AI) models in our place of work. The International Energy Agency estimates that every bit of internet protocol traffic, associated with consumer or business use, triggers another 5 bits of energy usage in the actual data center hosting the workload.
The most recent estimates by Masanet et al suggest that global data center energy use reached 205 TWh, about one percent of global electricity consumption, in 2018. However, it is true that the hyperscale data centers that power the world’s IT clouds have made major strides in energy efficiency over the last decade, managing to keep a lid on energy usage through impressive improvements in computing power, use of virtualization technologies and storage.
Yet these past improvements in efficiency give scant cause for complacency, for at least two reasons:
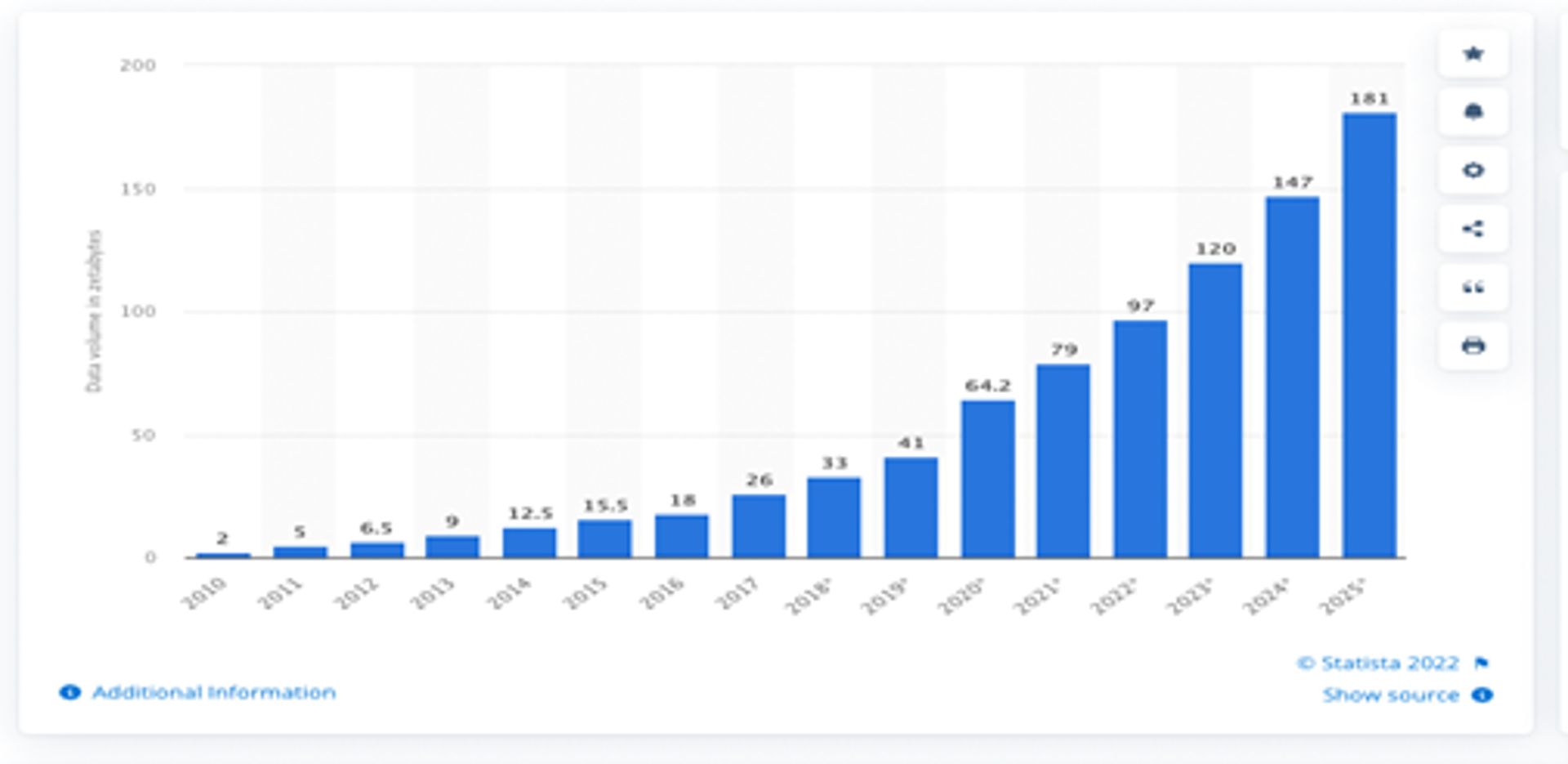
- Data volumes are set to reach stupendous levels over the coming decade, growing from about 79 zettabytes in 2021, to a projected 181 zettabytes by 2025. All driven by massive growth in next-generation technologies such as AI, mobile commerce, machine learning, internet of things, virtual and augmented reality, computer-generated holography and, at some stage, quantum computing (See Figure).
- Incremental improvements in energy efficiency through the use of public cloud technologies are likely to become harder to achieve, with much remaining data residing on private data centers that are hard to move to the cloud for regulatory, logistical or privacy reasons. The reality is that much of the “low-hanging fruit” in cloud-driven energy efficiency has already been harvested.
Figure: Volume of data created, captured, copied and consumed worldwide from 2010 to 2024 (zettabytes)
Source: Statista
An economic solution
With technology solutions alone unlikely to fully address the carbon and other resource impacts of data use, it seems timely to ask what role economic tools and incentives could play in optimizing data usage to reflect its wider social benefits and costs. We put forward three areas that could form part of an emergent economics toolkit for tackling data waste.
- Emerging methods for pricing data:
When it comes to optimizing data usage and storage from a sustainability perspective, businesses and policymakers have to balance two competing objectives.
On one hand, there is an urgent imperative to tackle data waste, the private and social costs associated with storing digital data that is no longer needed due to age, degradation of quality or redundancy in some form. By its nature, the extent of data waste is hard to measure precisely, but a variety of sources suggest it is a significant problem for businesses. Studies from the US healthcare sector suggest that somewhere between ten percent and 22% of medical records are duplicated. In other cases, data may be of marginal value due to the use of disparate sources or formatting methods. Even more problematic is that by one estimate more than half (55%) of business data is “dark data” – potentially valuable information that companies are storing but are unable to retrieve or use productively.
On the other hand, there are often very good reasons for organizations storing more data than they need on a day-to-day basis—for disaster backup, regulatory compliance purposes, or as training datasets for AI tools, for example. What’s more, organizations may want to keep some types of data in the expectation that they will find new innovative uses in the future. As new types of data (geo-spatial, social media, sensory, biometric, and others) emerge over the next decade, it is not hard to imagine new and exciting use cases with strong societal benefits. Examples include new ways to track biodiversity loss and changes in land use, as well as better ways to identify the health impact of climate change and pollution.
The challenge, therefore, is what to discard and what to retain. Here, economic principles can provide guidance. For internal data within organizations, one approach could be shadow pricing of digital data sources, with internal charging mechanisms to reflect the energy and other costs of storing large volumes of data in databases and on servers. Another approach, borrowed from financial markets, could be the use of options contracts, where a third party contracts the option to buy the data at a specified future date. Such contracts would also reveal the market-determined future ‘option value’ of that data.
Options pricing admittedly has limitations. It depends on the seller having ownership rights to the data. It may work less well for public or semi-public datasets where ownership rights are more opaque and societal benefits more diffuse. More problematically, markets have short time horizons and may struggle to identify long-term future use cases. A case in point is the example of the UK Coal Authority, which has started revisiting 100-year-old colliery maps to help energy companies identify geo-thermal sources of energy that can provide sustainable heating sources for towns in the North of England. Would market mechanisms at the time have foreseen such future use cases? It seems unlikely.
In these instances, alternative decision-making frameworks could be developed that value data according to factors such as its uniqueness, the likelihood it could be easily replicated in the future and the extent to which its use is limited to specific purposes. The public sector might also want to pay attention to private, public and third sector data where future social benefits could accrue to those other than the data owner.
- Assessing the value of shared data:
Data sharing can be doubly beneficial for sustainability outcomes: by reducing the need for costly replication of data (depending on how it is shared) and by enabling shared solutions to societal and business problems. Yet perhaps the majority of socially useful data is not shared, either for commercial reasons or because organizations lack the resources to extract and disseminate it.
Economics can contribute through more frequent and better frameworks for the valuation of shared data—at the macro and sectoral level. One of our recent studies for the Open Data Institute, for example, found that a 25 percent increase in data sharing could boost GDP for the world’s 20 largest economies by somewhere in the region of $47.3 bn to $118.3 bn. Another of our studies assessed the economic benefits of integrated data sharing for the UK’s Climate Resilience Demonstrator (CReDo), which brings together water, energy and telecoms network providers to share climate data and modelling in a common data environment. Modelling the economic benefits across a range of different future flood scenarios, we estimated that CReDo could deliver economic benefits in the range of £6m - £13 million across the East Anglia region over the period 2020-2050, and national benefits of £81m to £186m during the same time frame (in constant prices).
- Creating optimal choice architectures for data use:
A final area for sustainability data policy could be greater use of nudge mechanisms and incentives to promote the socially efficient use of data. Optimal choice architecture has, for better or worse, become increasingly prevalent in online markets, with AI-based recommendation engines shaping the products, services and choices we are presented with. While still a controversial area, online choice architecture and digital nudges have proved to be effective in certain areas of digital safety and online content moderation, for example by using the power of the crowd to enforce norms and standards in online gaming, or through the use of conversational bots in social media that ask users to pause before submitting aggressive or inflammatory comments. Given that the environmental impact of most data choices is largely invisible to individual users, better online choice architecture could play an important role in changing individual behaviour, for example by highlighting the environmental cost of downloading a movie versus streaming it, or by reminding users to delete multiple previous copies of a file as they write a report. Optimal choice architecture can also play a role in regulatory and policy design, incorporating, for example, financial or regulatory incentives for data waste reduction or for the sharing of data by enterprises, especially in socially beneficial areas such as scientific research and the environment.
Data policy remains a neglected but important component of sustainability policy. Alongside advances in technology, a more systematic use of economic principles and tools—around pricing, incentives, sharing mechanisms, and valuation techniques—would help promote more sustainable data usage, bolster socially useful innovation, and help enterprises and governments advance more rapidly to net-zero goals.
Authors


Sarah has been advising the public and private sectors on the effectiveness and value for money of government policy since 2001.
View profile